使用golang编写简单的游戏助手
最近工作关系需要学习golang,除了工作时间学习之后,觉得自己还需要其它练习。正好最近在玩儿勇者斗恶龙6(Dragon Quest VI,以下简称DQ6)。第一次玩DQ6还是在中星微,当时发现“我”只是主角在现实世界的一个梦,并可以在现实世界和梦的世界中穿行的时候,相当震撼。后来,盗梦空间上映之后,我又学会了做“梦中梦”。哦,扯远了。。。
问题描述
有时觉得DQ6反复的战斗画面很消耗我的精力,希望从进入如下战斗画面开始,到最后战斗结束退出,全部自动完成,并汇报结果。本文描述如何用golang,opencv,tesseract实现该功能。机器学习现在也不会,希望将来能用机器学习实现更多功能(一直希望把DQ4打通:))
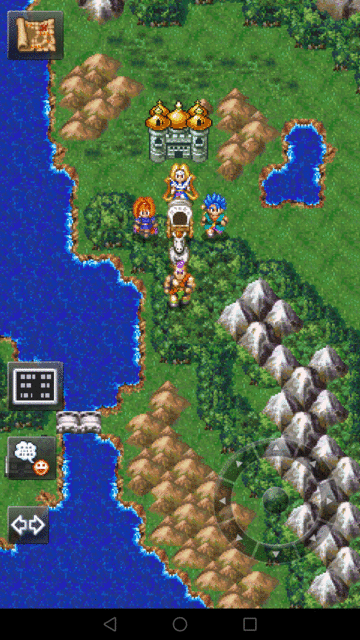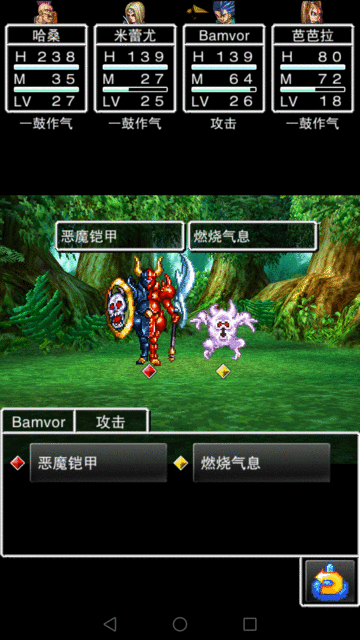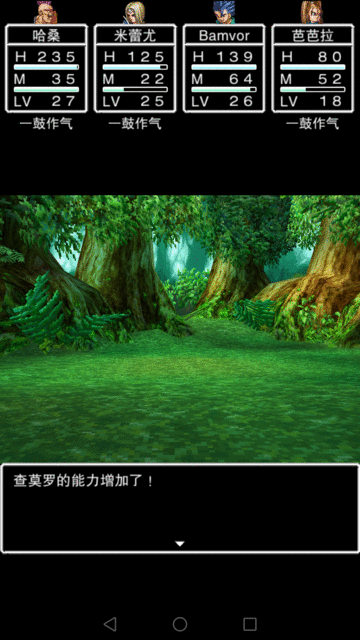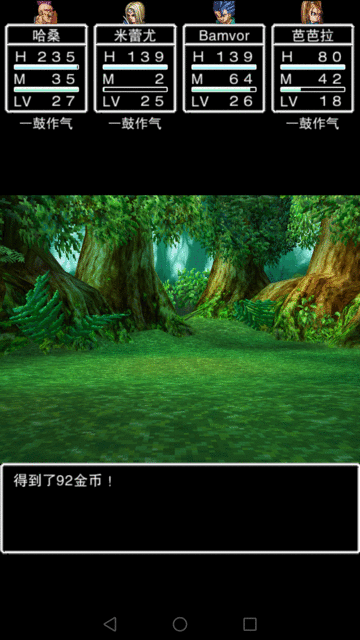
尝试用简单的抓图和模拟点击解决
直观的想法是通过android手机adb截屏,模拟点击。原来做Android内核时曾经做过类似的事情。
基本命令
- 抓图并保存到指定目录:
adb shell screencap -p /storage/sdcard0/bamvor/dq6.png - 模拟点击,当年做Android2.3到时候,我是直接通过input设备驱动的接口模拟触摸屏的点击。现在发现android提供了input命令,可以通过”input tap”实现单击,”input swipe”实现拖拽:
adb shell input tap x y adb shell input swipe x0 y0 x1 y1 interval_ms
准备每个事件的脚本
- 在大地图散步碰敌人。
在地图上主角静止不动的时候,固定位置有主菜单,方向键等按钮。这个步骤比较简单,抓图并点击固定位置就好了:
- 抓图
adb shell screencap -p /storage/sdcard0/bamvor/dq6.png adb pull /storage/sdcard0/bamvor/dq6.png adb shell rm /storage/sdcard0/bamvor/dq6.png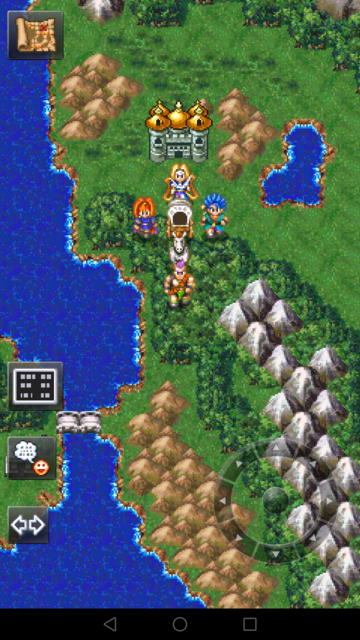
- 比较固定位置是否有主菜单,如果有说明在地图,否则跳过这一步。

- 按住一个方向键使主角走一定的距离,保证主角的一定范围内移动即可。
# 向西走1000ms adb shell input swipe 900 2020 900 2020 1000 # 向东走1000ms adb shell input swipe 1300 2020 1300 2020 1000
- 抓图
- 战斗画面监测和攻击
- 从前面gif动画可以看到,“战斗”按钮后面有一部分背景,同时背景是变的,不能通过比较图片是否一致判断是否开始战斗。为了可以直接比较图片,需要去掉又背景的部分,如图:
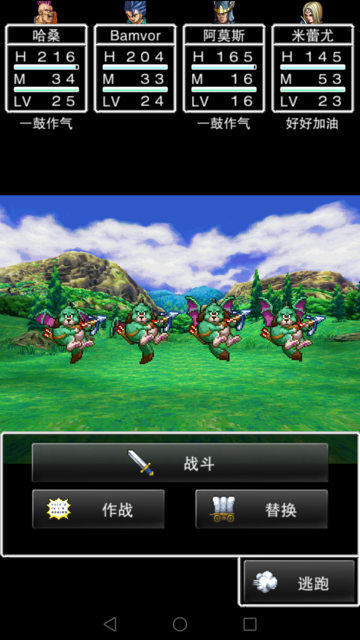 需要和下图比较;
需要和下图比较;
 发现进入战斗画面后,单击一次进入攻击菜单。
发现进入战斗画面后,单击一次进入攻击菜单。
adb shell input tap 130 1800 - 选择勇者的攻击菜单:类似上面战斗画面监测,如果勇者参加战斗,需要再点击两次。为了简化固定点击三次。
- 从前面gif动画可以看到,“战斗”按钮后面有一部分背景,同时背景是变的,不能通过比较图片是否一致判断是否开始战斗。为了可以直接比较图片,需要去掉又背景的部分,如图:
- 战斗胜利并退出战斗。 战斗胜利画面需要单击多次并且文字比较多,同时如果会有不同的信息(人名,新技能等等),比较全部可能的文字比较繁琐。当时想了个办法,监测最下面的光标。但是有个特殊情况最后一个图片(获取金钱)没有这个光标。因为战斗直接结束,人物升级等多种战斗结束事件要点击的鼠标次数差别比较大。没法通过多点击几次退出。最后想了个办法,如果30次抓图没有发现事件变化。就额外单击一次屏幕中间,这样就能退出战斗了。
这时候代码是这样的;
//...
func test_and_check_fighting_result() bool {
var result bool
src := gocv.IMRead("dq6.png", gocv.IMReadUnchanged)
rect := image.Rect(0, 2150, 1440, 2200)
dst := src.Region(rect)
golden := gocv.IMRead("golden_check_fighting_result.png", gocv.IMReadUnchanged)
dst_bytes := dst.ToBytes()
golden_bytes := golden.ToBytes()
ret := bytes.Compare(dst_bytes, golden_bytes)
if ret != 0 {
return false
}
fmt.Println("In check fighting result senario.")
result = click(750, 1200)
if !result {
return result
}
return true
}
//...
func main() {
var result bool
var false_count int
for {
cmd := exec.Command("/usr/local/bin/adb", "shell", "screencap", "-p", "/storage/sdcard0/bamvor/dq6.png")
err := cmd.Run()
if err != nil {
fmt.Println("Command finished with error: %v", err)
return
}
cmd = exec.Command("adb", "pull", "/storage/sdcard0/bamvor/dq6.png")
err = cmd.Run()
if err != nil {
fmt.Println("Command finished with error: %v", err)
return
}
cmd = exec.Command("adb", "shell", "rm", "/storage/sdcard0/bamvor/dq6.png")
err = cmd.Run()
if err != nil {
fmt.Println("Command finished with error: %v", err)
return
}
result = test_and_start_fighting()
result = result || test_and_check_fighting_result()
result = result || test_and_walking()
if !result {
false_count += 1
}
if false_count % 30 == 0 {
idle_click()
}
}
}
目前的问题
如果仅仅是为了能帮忙战斗,腾出手来去个洗手间。上面的代码基本够用了。但是有几个局限:
- 单张抓图速度慢,造成整个战斗时间比手工操作时间长。后续可以改进。
- 战斗结束时检查的光标(一个向下的小三角)大约是2Hz概率的闪烁,再加上false_count等30次才会退出战斗,退出战斗时间比较长。
- 退出战斗时不同的子事件有些信息是有用的。例如我希望攒钱的时候希望知道每次战斗挣了多少钱。我还希望知道人物学会了什么新技能,后续需要可以使用。
问题2和3其实就是要能识别出屏幕的文字。
文字识别
搜了下比较直接的文字识别方法就是用老牌开源软件tesseract。但是对于上述图文混合的情况,tesseract并不是很好的识别版面。所以需要预先的分析。文字识别也可以用云厂商的api,例如google vision api可以直接返回文字位置和文字内容。考虑到自己还是希望了解下可以怎么做。还是用更基础的工具组合实现。
矩形识别和剪裁
具体到DQ6的情况,可以通过识别图中最大的对话框(DQ6中对话框都是白色边界),并识别其中的文字。从pyimagesearch下载了shape-detection.zip的代码,代码用python写的。后续可以改为golang。经过测试这个代码可以比较好的发现最大的这个对话框。
对原有detect_shapes略做修改可以输出矩阵的左上和右下的顶点(x0, y0, x1, y1),这也是opencv crop函数(Region)所需的参数。
$ ./detect_shapes.py --image Dragon_Quest_VI__fighting_main_menu.png
9, 1724, 1431, 2420
相关python opencv函数是
- “findContours”得到每个形状的轮廓。
- “arcLength”和”approxPolyDP”判断是否是矩形。
- 如果是矩形找到矩形的左上和右下的顶点。
- 返回面积最大的矩形。
得到矩形左上和右下点的坐标就可以剪裁出这个对话框;
//crop the original.png to crop.png
rect := image.Rect(9, 1853, 1431, 2209)
src := gocv.IMRead("original.png", gocv.IMReadUnchanged)
dst := src.Region(rect)
gocv.IMWrite("./crop.png", dst)
文字位置识别
如果仅仅为了判断场景,识别出矩形后,通过tesseract识别文字,即使有错,也大致可以判断出场景。但是我这里希望能得到战斗结束后新道具,收入和人物新技能,所以需要比较准确的每行每列的文字。识别出不同行列的文字,也便于后续通过文字位置单击按钮。
google看到两个文字定位的方法。
- 一定是通过行列像素点统计(水平投影和垂直投影)得到文字位置; 【OCR技术系列之二】文字定位与切割,这个方法假设除了文字没有别的图形。对我来说基本够了。
- 另一个方式是通过https://stackoverflow.com/a/34262838/5230736>的opencv库。下载下来试了试,注释明确说明对象形文字效果不好,我发现的确识别不出中文(不知道是否参数需要调整?),英文位置识别比较准确。后续如果做自动化的BMC控制,可以考虑用这个库。
使用opencv把原图按照把上面detect_shapes输出的矩阵剪裁
 再使用上面说的水平投影得到每行文字
再使用上面说的水平投影得到每行文字
 由于图片保留了部分边框,所以我设置了文字的最小高度等信息过滤的边框。实践表明带一点边框会影响识别效果,后文描述了如何去除边框。
由于图片保留了部分边框,所以我设置了文字的最小高度等信息过滤的边框。实践表明带一点边框会影响识别效果,后文描述了如何去除边框。

代码最后会输出每行文字的位置,并截图
192:Dragon_Quest_VI bamvor$ go run locate_the_font.go
0, 3, 1422, 104
0, 104, 1422, 191
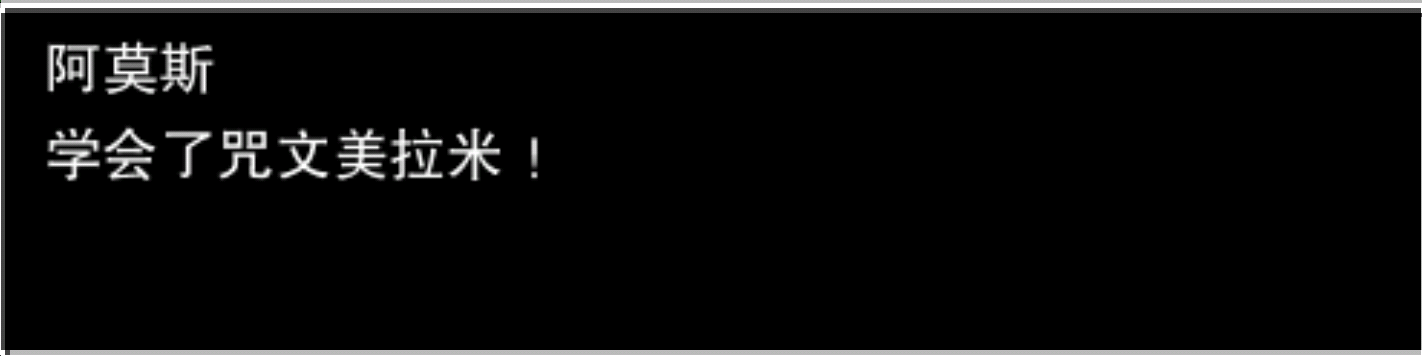
例如”0, 104, 1422, 191”的图片:

对它进行文字识别:
$ tesseract /path/to/img stdout -l chi_sim
Warning. Invalid resolution 0 dpi. Using 70 instead.
Error in boxClipToRectangle: box outside rectangle
Error in pixScanForForeground: invalid box
\ 学会了
咒
文美拉米
!
因为已经做了分行,可以用”–psm 7”强制按照一行识别:
$ tesseract /path/to/img stdout -l chi_sim -psm 7
Warning. Invalid resolution 0 dpi. Using 70 instead.
Too few characters. Skipping this page
OSD: Weak margin (0.00) for 8 blob text block, but using orientation anyway: 0
Error in boxClipToRectangle: box outside rectangle
Error in pixScanForForeground: invalid box
\ 学会了咒文美拉米 !
其实还没做完
- 确定按钮的中点
看到矩(Moments)这里被卡住了。没法理解为什么这样就能计算出每条边的中点。
cX = int((M["m10"] / M["m00"])) cY = int((M["m01"] / M["m00"]))参考:https://dsp.stackexchange.com/a/8521, http://zoi.utia.cas.cz/files/chapter_moments_color1.pdf
这样计算出中点,可以单击这个中点实现单击这个按钮。
-
由于矩阵边的干扰,有时识别的结果很差,所以需要预先去掉矩阵的边。前面findContours得到轮廓后,可以把轮廓画成背景色。 更好的办法是直接去掉很长的线。
- 有些情况下,战斗的彩色画面过亮,用灰度图像和投影得到了图片,没法得到文字区域。感觉还是先只提取字体的颜色或者直接通过算法识别可能为中文的区域比较好。
附录
- tesseract按照和使用
- 安装
brew install tesseract - 安装中文模型。
- 参数
- “-l”指定语言”chi_sim”表示简体中文。
- 页面分析方式,我再DQ6里面觉得常用的有3,7,12
Page segmentation modes: 3 Fully automatic page segmentation, but no OSD. (Default) 7 Treat the image as a single text line. 12 Sparse text with OSD.
- 安装